
MySQL存储引擎
该文是在阅读姜承尧的《MySQL技术内幕:InnoDB存储引擎》第2版的过程中的笔记,排版比较混乱,语言也不会刻意组织。
1. 不同引擎的特点
先介绍下MySQL中不同存储引擎的特点
1.1 InnoDB
InnoDB存储引擎最早由Innobase Oy公司1开发,被包括在MySQL数据库所有的二进制发行版本中,从MySQL 5.5版本开始是默认的表存储引擎(之前的版本InnoDB存储引擎仅在Windows下为默认的存储引擎)。该存储引擎是第一个完整支持ACID事务的MySQL存储引擎(BDB是第一个支持事务的MySQL存储引擎,现在已经停止开发)。
其特点是行锁设计、支持MVCC、支持外键、提供一致性非锁定读,同时被设计用来最有效地利用以及使用内存和CPU。
InnoDB使用聚集索引,因此其中的数据按照主键的顺序存放。如果创建表时没有显示的指定主键,则引擎会在表中选择一个唯一非空的索引做主键,如果表中没有这样的字段,则会为表创建一个隐藏的主键。
1.2 MyIsam
- 不支持事务,行级锁
- 支持表锁和全文索引
1.3 NDB
数据全部存放在内存中,主键查找很快
1.4 Memory DB
- 数据存放在内存中
- 默认哈希索引
- 只支持表锁
1.5 Archive
- 只能Insert和Select操作
- 支持行级锁
- 不支持事务
- 高速插入和数据压缩功能
1.6 Federated DB
- 不存储数据
- 主要是链接远程MySQL服务器的表
1.7 Maria DB
- 支持缓存数据和索引文件
- 支持事务和非事务的安全选项
SHOW ENGINES 命令可以查看当前服务器支持的存储引擎,同一张表,在不同存储引擎下的占用内存大小。
2. 链接MySQL服务器的方式
- TCP/IP
- 命名管道
- 共享内存
- UNIX套接字,需要客服端和服务端在同一台服务器
3. InnoDB存储引擎
3.1 线程
根据线程的不同作用,有以下几种线程:
- Master Thread:负责缓冲池中的数据异步刷新到磁盘,Master Thread 线程是InnoDB的主线程,下面的其他线程都是该线程在处理的过程当中,异步调用的
-
IO Thread:负责以下几种类型的io thread的回调
- write thread
- read thread
- insert buffer
- log io thread
- Purge Thread:undolog 回收
- Page Cleaner Thread:缓冲池脏页刷新到磁盘文件
3.1.1 Master Thread
该线程宏观上来看只有两个动作:每秒的操作和每十秒的操作。其内部的伪代码如下:
void master_thread(){
goto loop;
loop:
for(int i=0;i<10;i++){
thread_sleep(1)//sleep 1 second
do log buffer flush to disk
if(last_one_second_ios<5%innodb_io_capacity)
do merge 5%innodb_io_capacity insert buffer
if(buf_get_modified_ratio_pct>innodb_max_dirty_pages_pct)
do buffer pool flush 100%innodb_io_capacity dirty page
else if enable adaptive flush
do buffer pool flush desired amount dirty page
if(no user activity)
goto backgroud loop
}
if(last_ten_second_ios<innodb_io_capacity)
do buffer pool flush 100%innodb_io_capacity dirty page
do merge 5%innodb_io_capacity insert buffer
do log buffer flush to disk
do full purge
if(buf_get_modified_ratio_pct>70%)
do buffer pool flush 100%innodb_io_capacity dirty page
else
dobuffer pool flush 10%innodb_io_capacity dirty page
goto loop
background loop:
do full purge
do merge 100%innodb_io_capacity insert buffer
if not idle:
goto loop:
else:
goto flush loop
flush loop:
do buffer pool flush 100%innodb_io_capacity dirty page
if(buf_get_modified_ratio_pct>innodb_max_dirty_pages_pct)
go to flush loop
goto suspend loop
suspend loop:
suspend_thread()
waiting event
goto loop;
}
3.2 . 内存池
内存池除了占用大量空间的数据页(Data Page)、索引页(Index Page)还有其他必要的缓冲区:插入缓冲(insert buffer)、自适应哈希索引、锁信息(lock info)、数据字典信息
除了内存池,缓冲区还有重做日志(redo log)和额外内存池
3.3. Checkpoint
当InnoDB的缓冲区中,某数据页的数据发生变更,但还没有更新到磁盘文件时,则该页被称为脏页。脏页数据比磁盘上的数据新,所以需要将脏页数据更新到磁盘中对应的页当中去。若在数据更新的过程中服务器发生宕机,就会出现数据丢失的情况,为了避免这种情况,在缓冲区中的页变更之前,先写重做日志(Write Ahead Log),再修改页。如果发生数据丢失,可以通过重做日志来回复数据。
但是通过重做日志,如果数据量巨大,则将耗费大量的时间。
所以,Checkpoint技术的目的就是为了解决下面的这些问题:
- 缩短DB的数据恢复时间
- 缓冲池不够时,将脏页刷新到磁盘文件
- 重做日志不可用时,刷新脏页
在实际应用中,会发现,重做日志量大,那么在恢复的过程中,我们该从日志的什么地方开始恢复呢?应该恢复多少呢?这个就需要Checkpoint技术来解决。。。未完
3.4. InnoDB关键特性
InnoDB存储引擎的关键特性包括:
- 插入缓冲(Insert Buffer)
- 两次写(Double Write)
- 自适应哈希索引(Adaptive Hash Index)
- 异步IO(Async IO)
- 刷新邻接页(Flush Neighbor Page)
上述这些特性为InnoDB存储引擎带来更好的性能以及更高的可靠性。
3.4.1 插入缓冲
在InnoDB中,其主键索引因为是聚集索引,所以在磁盘上写入数据的顺序是根据主键的自增顺序排列的。但是InnoDB表中除了主键索引还有其他的辅助索引,它们都是非聚集的,每次对其进行修改都会导致辅助索引的变更,如果这个变更数据量很大,那么对于磁盘的性能消耗是很大的。
InnoDB存储引擎开创性地设计了Insert Buffer,对于非聚集索引的插入或更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入;若不在,则先放入到一个Insert Buffer对象中,好似欺骗数据库这个非聚集的索引已经插到叶子节点,而实际并没有,只是存放在另一个位置。然后再以一定的频率和情况进行Insert Buffer和辅助索引页子节点的merge(合并)操作,这时通常能将多个插入合并到一个操作中(因为在一个索引页中),这就大大提高了对于非聚集索引插入的性能。
然而Insert Buffer的使用需要同时满足以下两个条件:
- 索引是辅助索引(secondary index)
- 索引不是唯一(unique)的
辅助索引不能是唯一的,因为在插入缓冲时,数据库并不去查找索引页来判断插入的记录的唯一性。如果去查找肯定又会有离散读取的情况发生,从而导致Insert Buffer失去了意义。
3.4.2. 两次写
当InnoDB正在刷新页到磁盘上时,如果还没写完,比如只写了4KB(一页默认16KB),这个时候,数据库所在服务器宕机了,这个时候,磁盘上的这个页数据是不完整的,你可能会说可以通过redo日志修复,但是redo日志修复是需要原磁盘状态是完整的。在磁盘不完整的情况下,redo日志就无法恢复了。这个时候就需要两次写了。
简单来说,两次写就是在页刷新之前,做一个页的副本,当需要重做时,通过页的副本将磁盘页还原到原来的状态,在通过重做日志恢复数据。
其结构如下:
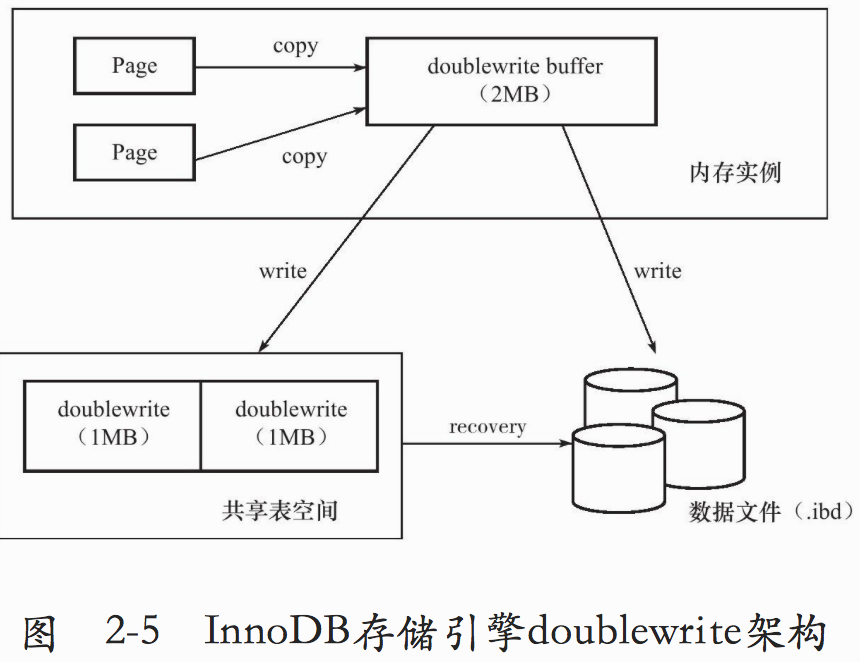
所以,插入缓冲提高了DB的性能, 那么,两次写便提高了DB的可靠性
3.4.3. 自适应哈希索引
这个概念就很好理解了,当对某个页进行多次的连续的查询,且查询条件是等值查询(非范围查询),同时满足下面的条件时:
- 以该模式访问了100次
- 页通过该模式访问了N次,其中N=页中记录*1/16
InnoDB存储引擎就会自动创建一个哈希索引指向这个页。
为什么要这么做呢?
很简单,InnoDB的索引数据结构是B+Tree,其查找时间和树的高度有关。但哈希查找的时间复杂度是O(1)。其原因就不道自明了。
3.4.4. 异步IO
当查询磁盘上连续的页(不一定要是连续的),需要多次进行磁盘IO时,此时,引擎会将多次IO合并成一次IO,减少磁盘IO次数,达到提高性能的目的。
不得不说,这些人的脑瓜子真是聪明啊,想尽一切办法提高这玩意儿的性能和可靠性。
3.4.5. 刷新临近页
和异步IO一个道理。
4. 文件
- 参数文件:告诉MySQL实例启动时在哪里可以找到数据库文件,并且指定某些初始化参数,这些参数定义了某种内存结构的大小等设置,还会介绍各种参数的类型。通过命令
mysql --help|grep my.cnf来寻找 - 日志文件:用来记录MySQL实例对某种条件做出响应时写入的文件,如错误日志文件、二进制日志文件、慢查询日志文件、查询日志文件等。
- socket文件:当用UNIX域套接字方式进行连接时需要的文件。
- pid文件:MySQL实例的进程ID文件。
- MySQL表结构文件:用来存放MySQL表结构定义文件。
- 存储引擎文件:因为MySQL表存储引擎的关系,每个存储引擎都会有自己的文件来保存各种数据。这些存储引擎真正存储了记录和索引等数据。本章主要介绍与InnoDB有关的存储引擎文件。
4.1 日志文件
MySQL数据库中常见的日志文件有:
- 错误日志(error log)
- 二进制日志(binlog)记录了对数据的所有操作,用于恢复数据和分布式情况下的数据同步
- 慢查询日志(slow query log)
- 查询日志(log)
- 查找错误日志路径:
SHOW VARIABLES LIKE'log_error'\G; - 查找慢查询日志:
SHOW VARIABLES LIKE'long_query_time'\G;
5. 表
众所周知,InnoDB中创建表时,会按照如下规则,为表创建主键索引:
- 如果表创建时显式的指定了主键索引,则被指定的列即为主键索引
- 如果没有指定主键索引,且有唯一非空的索引,则唯一非空的列即为主键索引(如果有多个唯一非空的索引,取定义表时,最先定义的唯一非空索引为主键索引)
- 如果上述情况都没有,则InnoDB引擎为表创建一个6字节的隐性主键索引
5.1 InnoDB数据存储逻辑
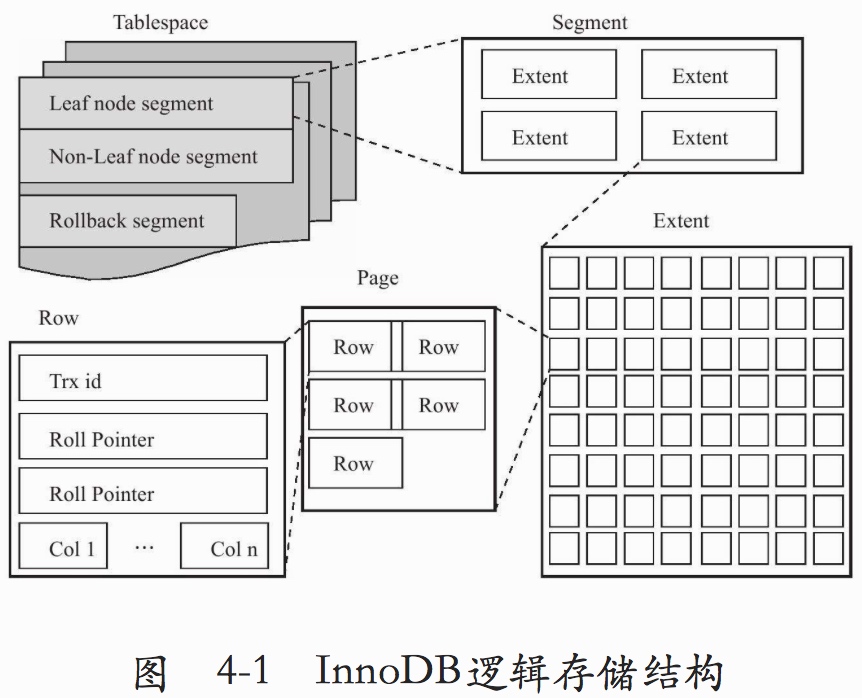
如图,InnoDB中所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block)
从图中可以看出,所有的数据都存放在表空间中。有一点需要注意的是,默认情况下,InnoDB中所有的表共享一个表空间:ibdata1,但当配置参数:innodb_file_per_table启用时,每张表的数据就会单独放到表自己的表空间,而这个表空间存放的数据有:真实数据、索引、插入缓冲Bitmap页。而其他类的数据如:回滚信息(undo)信息、插入缓冲索引页、系统事务信息、二次写缓冲等还是存放在共享的表空间中,即:ibdata1.
每个页默认为16KB,每个区默认大小为1MB,所以,每个区有64个连续的页。现在的InnoDB版本中,还有能为页压缩的功能,可以压缩到2KB、4KB、8KB。
5.2 行格式
由上可知,InnodDB存储的最小单元是Row,即行。
老版本Row的存储格式有:
- Compact
- Redundant
新版本InnoDB 1.0.x开始,Row的存储格式有:
- Compressed
- Dynamic
每种存储格式存储数据的方式不一样,这里不做详细说明
既然每个页的默认大小是16KB,或者说,每个页都是有默认大小的。而每个页的官方默认最多存储行记录的算法是:(16KB/2-200),即7992行。这里就牵扯到一个行溢出的概念了。
我们考虑极端的情况,一个表的行只有一个类型的varchar类型的列。那么,当varchar的长度是多少的时候,会发生行溢出呢?
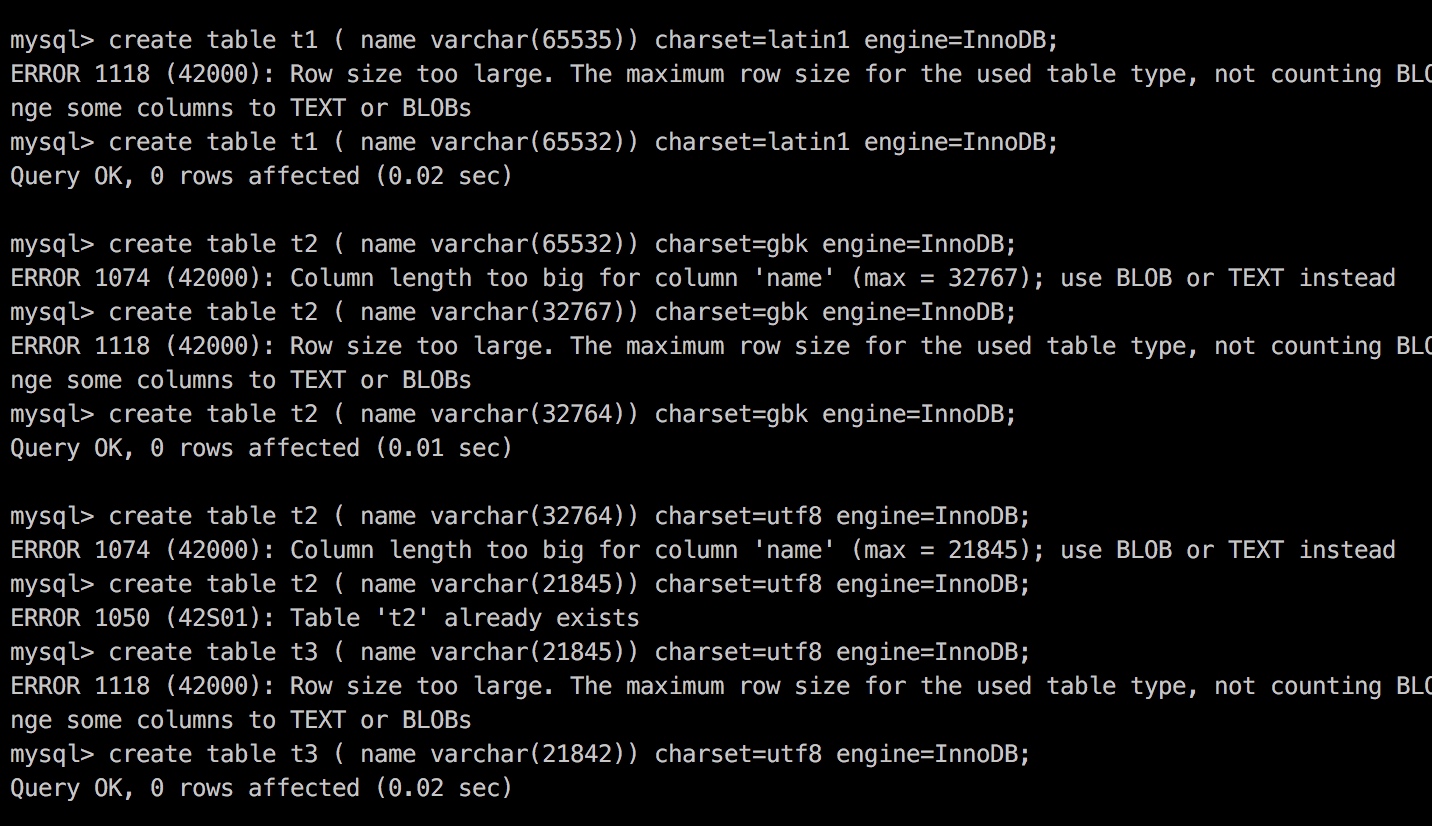
根据图上的实验,可以得出下面的结论:
- latin1编码方式下,行的最大数据长度为65532,另外有2字节表示长度,1字节表示是否为NULL;
- GBK编码方式下,一个字符占用两个字节,就可以解释图中的结果;
- UTF8编码,一个字符占用三个字节
另外,MySQL官方手册中,一行中的所有列长度的和也不能超过65535.
一个页的只能存储16KB的数据,只有16384个字节,当一行数据超过一页的大小时,InnoDB是怎么存放数据的呢?
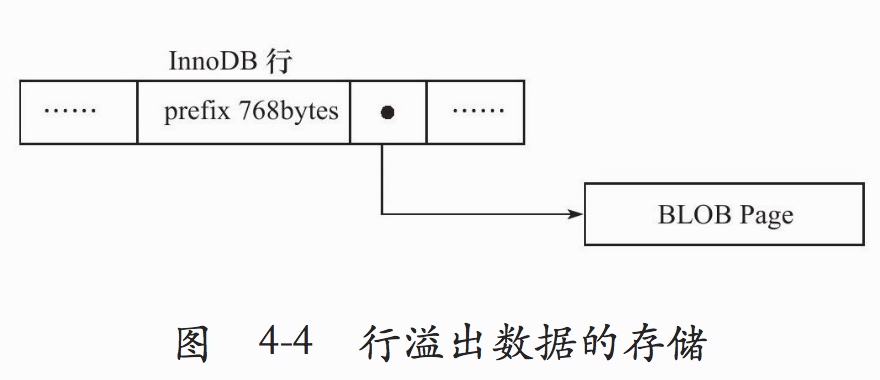
如上图,当页中发生行溢出时,为了保证索引结构的平衡,溢出的数据存放在BLOB PAGE中,即在其他的表文件中(这里不是很确定),通过指针指向这部分数据。注意这里的页中只保存了行的前面的786个字节。
我们知道,InnoDB表数据是索引组织的,而这里的索引是B+Tree结构的,为了保证B+Tree的平衡,一个页中至少需要两行数据,那么,这个时候InnoDB又是如果存储数据的呢?
每行的长度不超过8098
这是一个测试值。PS:为什么不是16KB*1024/2=8192?谁能告诉我?就算每行再减去三个字节,8192-6=8186也行啊,为什么?
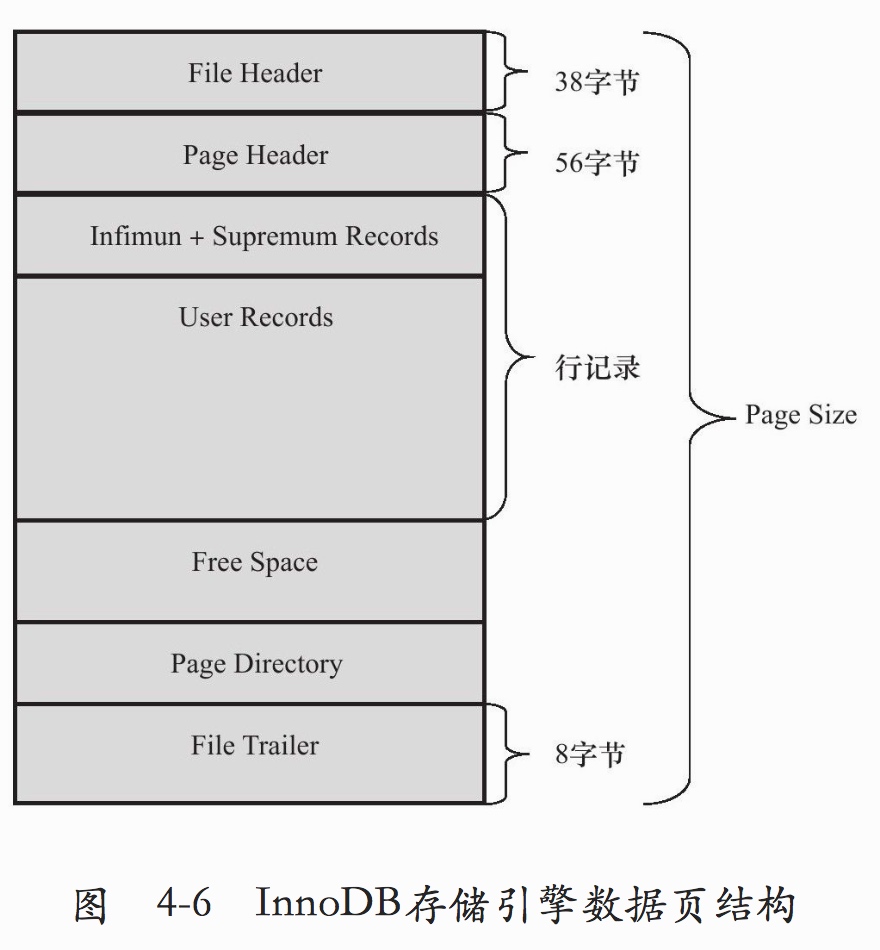
5.3 InnoDB数据页结构
如下图:
5.4 约束
关系型数据库系统和文件系统的一个不同点是,关系数据库本身能保证存储数据的完整性
- 在数据库表中,通过主键约束和唯一键约束来保证实体表数据的完整性
- 在列中,通过对域设置合适的数据类型和NOT NULL来保证列数据的完整性
- 表与表之间通过外键约束保证实体之间数据的完整性
综上,对于InnoDB来说,提供的约束有:
- Primary Key
- Unique Key
- Foreign Key
- Default
- NOT NULL
6. 索引
InnoDB支持的索引类型:
- B+Tree 索引
- 全文索引
- 哈希索引
个人理解,表级别的索引类型有:
- 聚集索引
- 非聚集索引
列级别的索引类型:
- 主键索引
- 辅助索引
- 唯一索引
- 联合索引
- 覆盖索引(?待论证)
查看表的索引:show index from table_name
6.1 B+Tree
B+Tree 的插入操作
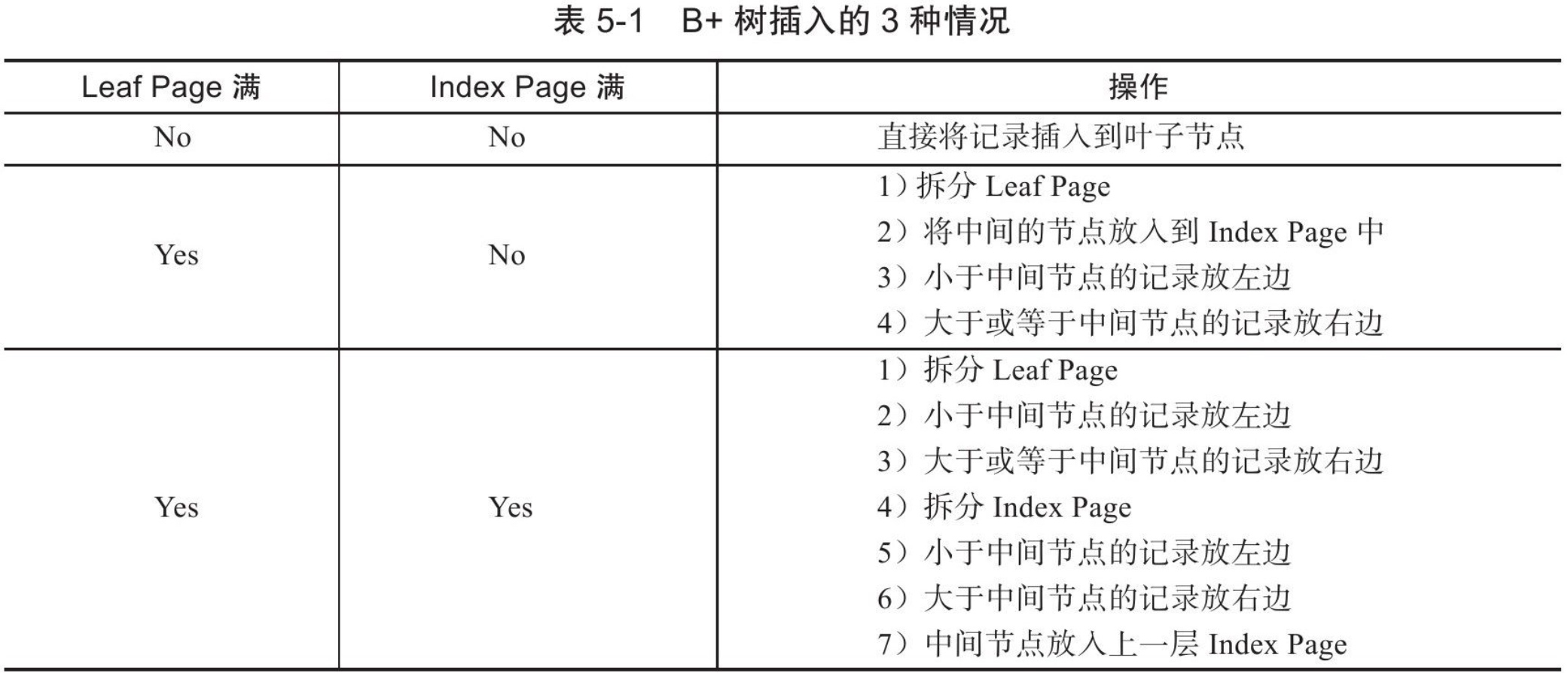
B+Tree 的删除操作

数据库中的B+Tree索引分为聚集索引和辅助索引,辅助索引又叫非聚集索引。
6.1.1 聚集索引
- 聚集索引按照表的主键构造一颗B+Tree,叶子节点存放表的行数据,叶子节点也叫数据页。这里的页和存储逻辑中的页不是一个概念
- 一张表只能有一个聚集索引(即主键索引)。为什么只能有一个聚集索引呢?为什么不能有两个或者多个呢?根据聚集索引的特点知道,聚集索引包含了表所有的行数据,当然可以根据其他列创建聚集索引,这个时候,所有的数据又会放到这个聚集索引的叶子节点中,这样岂不是有多少个聚集索引就会有多少倍的数据了。就是说,每多一个聚集索引,表占用的空间就会多一倍。这是一个,另一个是,聚集索引是顺序组织数据的,所以不会有重复键出现的问题,因为是聚集索引就是表的主键,它唯一非空。但是其他列会出现重复的KEY,这个时候,数据就不好组织了。其实从上面两点考虑,出来的结果就是,如果一定要在非主键列创建索引,该是什么样类型的索引呢?这就是后面要说的辅助索引,即非聚集索引
- 数据页之间用过双向链表链接,链表的好处就是通过主键,快速扫描整个表
- 聚集索引对数据的组织是逻辑顺序的,而不是物理顺序的。这个很好理解。
6.1.2 辅助索引(非聚集索引)
- 一个表可以有多个辅助索引
- 辅助索引存放的是该索引的KEY值对应的行的主键值。根据这个特性,如果一个辅助索引的高度为3,对应表的聚集索引高度也为3。则通过辅助索引查找数据,一共需要6次IO
Mysql中,添加或者删除列、索引的这类DDL操作,MySQL数据库的操作过程为:
- 首先创建一张新的临时表,表结构为通过命令ALTER TABLE新定义的结构。
- 然后把原表中数据导入到临时表。
- 接着删除原表。
- 最后把临时表重名为原来的表名。
可以发现,对于量很大、读写频繁的表来说,这样的操作会导致操作时,Mysql服务不可用。
6.1.3 联合索引
联合索引的数据结构
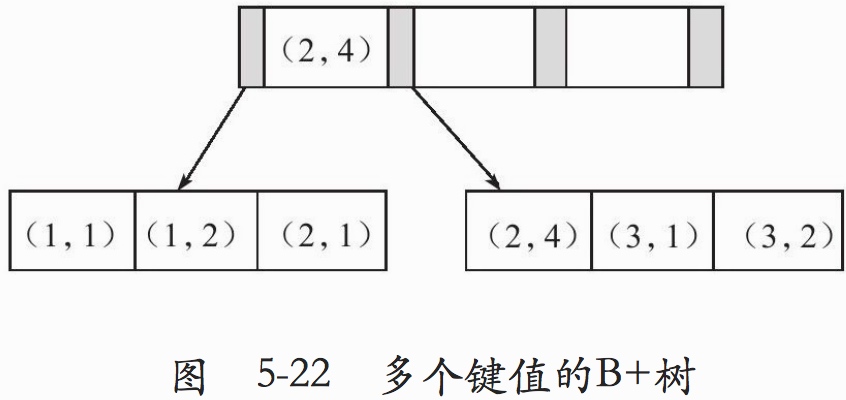
联合索引应用过程中,主要需要考虑的就是创建联合索引的顺序。判断查询语句是否能够用到该联合索引。
在获取数据和统计数据时,联合索引表现是不一样的,如下:
表 buy_log中有userid和buy_date两列,userid为主键索引,(userid,buy_date)为联合索引,则:
SELECT * FROM buy_log WHERE buy_date>='2011-01-01'AND buy_date<'2011-02-01'这个获取数据的查询没有用到什么索引SELECT count(*) FROM buy_log WHERE buy_date>='2011-01-01'AND buy_date<'2011-02-01'则用到了(userid,buy_date)这个联合索引,这里就涉及到下面的覆盖索引概念了。这里之索引会用到这个索引,一是因为不获取数据,二是buy_date在这个索引中是已经排好序的了
6.1.4 覆盖索引
覆盖索引即从辅助索引中就能得到需要查询的数据,而不需要通过聚集索引获取数据。因为辅助索引不包含所有的数据,所以通过辅助索引获取数据就可以减小IO操作,加快数据读取的速度。
还是上面的表结构,下面的语句都可以用到(userid,buy_date)这个联合索引
SELECT userid FROM buy_log WHERE buy_date>='2011-01-01'AND buy_date<'2011-02-01'SELECT userid,buy_date FROM buy_log WHERE buy_date>='2011-01-01'AND buy_date<'2011-02-01'SELECT buy_date FROM buy_log WHERE buy_date>='2011-01-01'AND buy_date<'2011-02-01'
因为要获取的这些数据在联合索引中都有,不需要通过聚集索引获取。
6.1.5 InnoDB查询优化器
通过对上面几种索引的了解,我们知道,InnoDB查询优化器在选择索引时,会根据各列索引情况,以及要获取的数据的情况,选择合适的索引。
MySQL查询执行的路径:
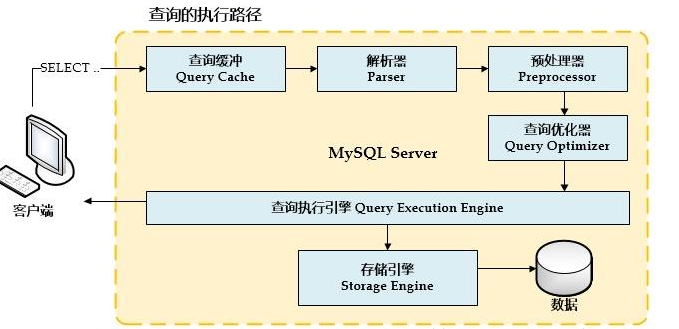
步骤:
- 客服端发送一条查询给服务器
服务器先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一个阶段。从Mysql8.0开始,已经去掉了查询缓存。因为查询缓存命中的条件很严格。- 服务器端进行SQL解析、预处理,在由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询
- 将结果返回给客户端
例如,表test有a、b、c三列,a是主键索引,同时也给a创建了一个辅助索引a_1
CREATE TABLE `test` (
`a` int(11) NOT NULL AUTO_INCREMENT,
`b` int(11) NOT NULL DEFAULT '0',
`c` int(11) NOT NULL,
PRIMARY KEY (`a`),
KEY `a_1` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
表中有如下数据:
select * from test where a > 10 and a < 10000;
上面的查询语句会使用主键索引来扫描表,其explain为:

而
select a from test where a > 10 and a < 10000;
则会使用a_1这个索引,其explain为:

所以在分析查询语句会用什么索引时,首先要确认的是要取得数据列在哪一个索引范围内。
-
2006年该公司已经被Oracle公司收购。 ↩