
顾名思义,主从复制就是将主库中的数据复制到从库中。从库可以有多个,同时主库和从库之间的网络拓扑有很多种组合方式,这里不做介绍。
为什么需要主从同步?
- 负载均衡 通过Mysql主从同步,可以将读操作分不到各个从库服务器上。实现对密集型应用的性能优化,并且实现方便。
- 容灾 避免单点故障,数据恢复,高可用性
- Mysql升级测试 可以在从库上使用高版本的Mysql,保证在升级全部实例前,查询能够在从库正常执行。
同步原理
简单来说,同步有三个步骤:
- 在主库上把数据的变更记录到Binary Log中
- 从库将主库的日志复制到自己的Relay Log中
- 从库读取Relay Log中的事件,将其重现在数据库中
Mysql同步原理图:
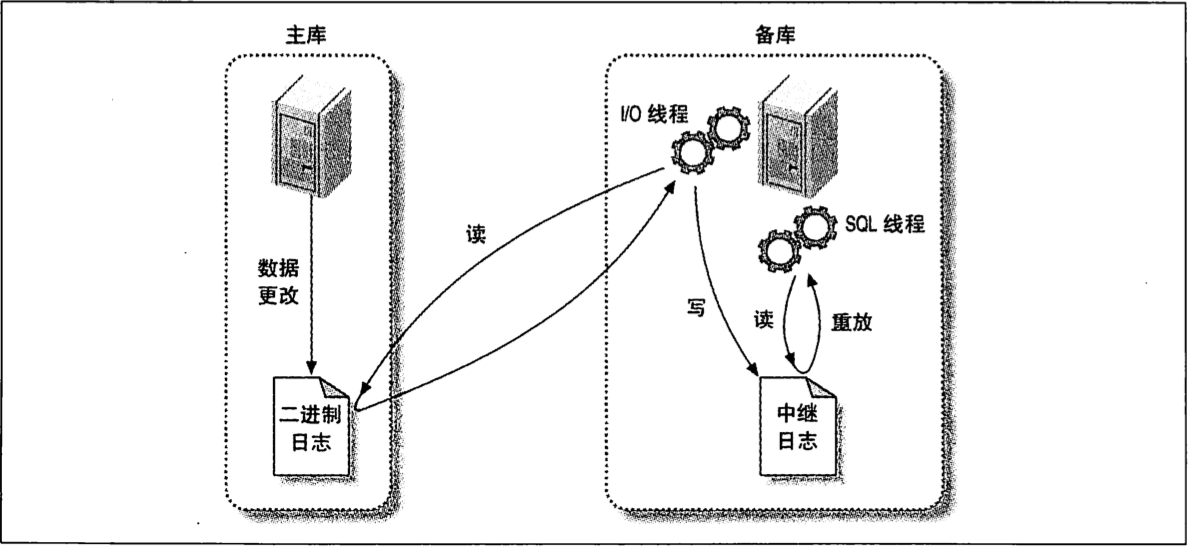
第一步是在主库上记录二进制日志,每次在数据变更事务提交前,主库将数据更新的时间记录到二进制日志中。注意这里的顺序,是先记录日志,才提交事务的。所以这里还是会对性能上有所消耗的。
下一步,从库启动一个I/O线程,与主库建立连接,然后在主库上启动一个二进制转储(binlog dump)线程,binlog dump线程会读取主库上的二进制日志中的事件,从库的I/O线程会将接收到的事件记录到自己的Relay Log中。
上面的binlog dump线程不会对Binary Log中的事件进行轮询,如果它追赶上了主库的最新事件,会进入睡眠状态,直到主库发送信号通知其有新的事件产生时,才会被唤醒。
从库的SQL线程执行Relay Log中的事件,从而实现数据库中数据的更新
这种主从同步的架构实现了获取数据变更事件和数据变更重现事件的解耦,两个事件的产生和处理可以异步进行。但也可以看出其中的瓶颈所在,当并发写操作过大,导致事件大量产生,但从库的事件重现线程同时只能有一个且串行执行,此时就会有数据一致性上的延迟。
数据复制的原理
上面说了数据变更事件从主库到从库的同步原理,但如何将事件转换成数据的变更呢?
在Mysql中有两种方式,语句复制和行复制
基于语句的复制
在Mysql 5.0 之前的版本中,只支持该方式的数据复制,也称为逻辑复制。在该模式下,主库会记录那些造成数据更改的操作,当从库读取并重现这些事件时,实际上只是把主库上执行过的SQL再执行一遍。这种方式既有好处也有缺点。
好处:
- 简单明了
- 该模式时,Binary Log中的事件更加紧凑,相对行复制而言,日志传送占用的宽带更少
缺点:
- 存在一些无法被正确复制SQL,例如:使用了CURRENT_USER()的函数语句(主从服务器的用户可能不是同一个),存储过程和触发器在该模式下也可能存在问题(这里不深究)
- 事件必须是串行的,同时需要更多多长时间的锁
基于行的复制
Mysql 5.1 中开始支持基于行的复制,这种方式将实际数据记录在Binary Log中,从库读取日志事件,直接将数据写入从库中,也就是说,相对于语句复制,这种方式是直接将最终的数据写入DB文件中,忽略了SQL语句中的逻辑。
从原理上不难知道,由于无须重现主库的查询逻辑,其能够更高效的复制数据。
但凡事有利有弊,对于少量行的数据变更,这种方式非常高效。但对于下面这种数据变更,基于语句的复制方式,其代价就会小很多:
UPDATE TABLE_NAME SET COLUMN_NAME = 0;
由于这条记录更新了全表,使用基于行的复制开销就会很大,因为每一行的变更事件都会被记录到Binary Log中。其带来的日志复制和数据复制的负载就会很高,对于主库来说,由于要在事件全都写入日志后才提交事务,会降低其支持的并发度。对于从库来说,事件重现时间延长导致数据一致性延时性更高。
比较来看,没有哪种模式对所有的情况都是完美的。Mysql能够在这两种模式之间动态切换,默认情况下用的是基于语句的复制方式。但如果发现有语句无法被正确的复制,就切换到基于行的复制模式。
-- wms_failed_jobs 只保留过去一个月的失败消息
select id from wms_failed_jobs where failed_at<='2018-05-01 00:00:01' order by id desc limit 1;
delete from wms_failed_jobs where id<=这里是上面查到的id;
-- 索引、数据整理
OPTIMIZE TABLE wms_failed_jobs;